Outils et démarche
Simple ou complexe, l’utilisation de l’informatique dans les travaux des historiens est aujourd’hui commune, sinon obligatoire, « l’histoire numérique » n’est plus une particularité, tous les travaux historiques sont aujourd’hui numériques.
Il faut donc prendre en compte ce progrès, dans les démarches et possibilités, mais aussi dans les évolutions de notre science. Dans les chapitres précédents nous avons mis en avant certains aspects ou contraintes, que nous essayons de reprendre ci-dessous. Nous présentons aussi certains outils d’usage courant ou plus spécialisés.
Ce dernier chapitre sera un peu personnalisé, je me permettrai d’utiliser quelquefois le pronom personnel « je », car je détaillerai des expériences personnelles.
Démarche
L’utilisation de l’informatique dans les recherches en Histoire est ancienne, mais malgré les progrès techniques énormes, les principes et contraintes restent généralement identiques.

Par exemple, ci-joint un court extrait de la revue « la médiéviste et l’ordinateur », de 1982 (il y a 43 ans), qui décrit un projet avec les mêmes termes que dans nos différents articles précédents ainsi que ci-dessous.
Codage et saisie des données
L’objectifs du codage est, à partie d’un corpus très divers, souvent manuscrit, de rédacteurs différents, et même plusieurs langues, de transformer les variantes de mots ou noms vers un format standard unique (canonique). Cette opération est nécessaire si ces mots sont utilisés pour des traitements ultérieurs selon leur sens.
Une réflexion importante est quelquefois nécessaire, les règles d’uniformisation n’étant pas toujours évidente. Par exemple, entre le même mot au masculin et au féminin dans le corpus, les deux genres ont-ils le même sens et peut-on les regrouper, et si oui sur le masculin ou le féminin ?
Autre exemple, plus délicat, le prénom Marie. Au XIXe siècle, ce prénom est souvent donné même pour des hommes, et ne peut donc pas être utile pour déterminer le genre d’une personne. D’autres critères doivent être pris en compte.
En résumé, le codage et ensuite la saisie sont une étape d’uniformisation, mais aussi par conséquent de simplification des données, qui doit être soigneusement préparée, pour ne pas perdre (trop) d’informations éventuellement pertinentes pour le projet.
De même, il ne faut pas sous-estimer la durée de la saisie, qui représente toujours des mois, si ce n’est des années de travail et aussi prendre en compte son « poids », car la saisie, en général, ne peut pas être effectuée par des « petites mains », mais par les historiens eux-mêmes, trop de décisions (codage) doivent être prises au fur et à mesure.
Se pose également le problème des langues. Pour l’Histoire de France, suivant les époques on navigue entre le latin et le français, ancien ou moderne. Dans notre région il faut ajouter l’allemand, ancien ou haut, l’alémanique ou autres variantes, sans parler des écritures, gothique ou sütterlin.
Bref, cette étape est cruciale, et est la plus lourde. Il faut y consacrer le temps nécessaire, et y apporter tout le soin utile, la qualité des résultats du projet est directement liée à la qualité de cette tâche.
Validation des données
Dans les temps anciens, à l’époque de la carte perforée, après la saisie on pratiquait « la vérif », c’est-à-dire une deuxième saisie permettant de détecter les erreurs. Ce procédé, coûteux, est difficilement applicable chez nous. Mais il est cependant primordial de réaliser un minimum de contrôle sur les données après saisie.
Une partie des données (5 à 10%), par sondage aléatoire, devrait être confrontée à l’original, permettant ainsi de juger de la qualité de la saisie. Il est également souvent possible de développer de petits programmes informatiques, analysant les données textuelles, pour détecter des incohérences.
Cette étape doit aussi permettre de valider la pertinence des codages, ou de détecter de nécessaires harmonisations complémentaires (orthographe multiple de noms ou de mots).
Des analyses plus détaillées (de distribution, moyenne et médiane, écart-type etc.) sont des tâches de l’étape suivante, l’analyse, mais permettent souvent de détecter des anomalies, d’attirer l’attention sur des résultats non attendus. Dans ce cas, cela peut permettre une relance ou réorientation des recherches, mais cela peut aussi être le signe d’un problème de données. Pour faciliter les choses, le problème peut avoir pour origine la saisie ou le codage, mais aussi des biais introduits pas les rédacteurs des documents d’origine.
Cette étape de contrôle est importante, car les étapes de codage et saisie peuvent facilement générer des erreurs, et lorsque vous passez une année à saisir des dossiers d’instituteurs, il est préférable de lever le plus tôt possible tout doute.
Analyse des données
Cette étape est, formellement, la plus importante, c’est elle qui représente dans la démarche la partie « utile » pour l’historien.
En général, une première tâche est l’établissement « d’index », c’est-à-dire cette partie de la validation déjà mentionnées, qui est l’application simple de calculs statistiques de base (fréquence, distribution etc.). Ces résultats permettent « de déblayer le terrain », et ainsi de guider les recherches, de définir d’autres outils statistiques pouvant être appliqués au jeu de données.
Nous ne donnerons pas ici plus de détails, le spectre des possibilités de ces outils est trop grand, et leur application encore plus, chaque projet est un cas particulier. Mais les lois statistiques sont relativement simples, normalement à la portée d’un historien.
Constantes des projets
La démarche telle qu’esquissée ci-dessus est assez générale, et se retrouve en gros dans tous les projets. Il y a d’autres points qui sont aussi plus ou moins des constantes dans nos projets.
La saisie de notes (ou commentaires) : dans beaucoup de cas il est important de prévoir, dans les outils de saisie, la possibilité d’intégrer des notes, textes libres soit explicitant des détails de la saisie, soit commentaires rédigés lors de la création des documents par le rédacteur.
Les chapitres précédents ont données des exemples de l’utilité et de l’importance des notes.

- Modèle Base de Données
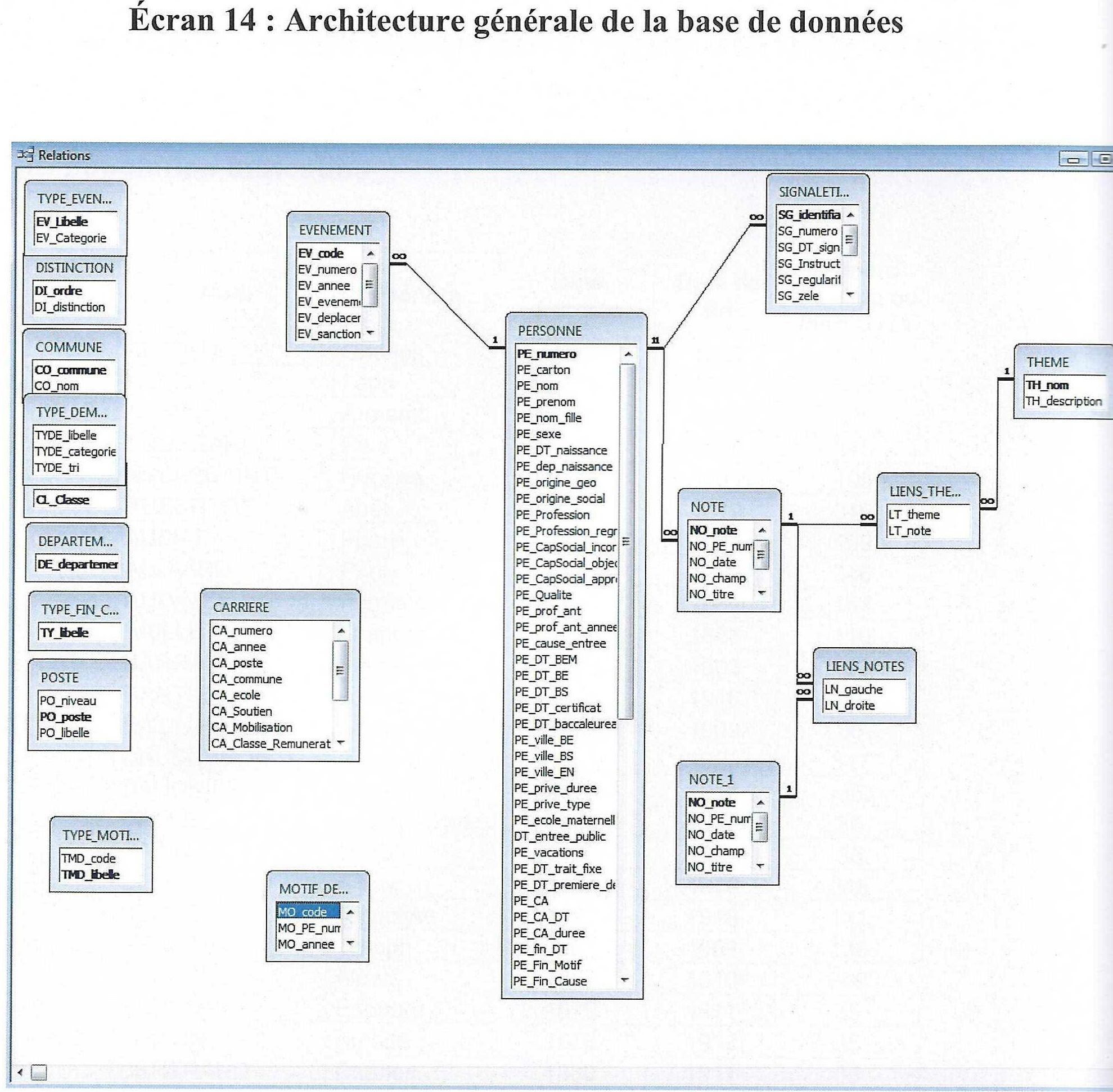
Nécessité d’un appui technique ? nous examinerons ci-dessous les outils informatiques utiles pour nos projets, et nous verrons deux catégories, deux niveaux de complexité.
Tout le monde a plus ou moins les connaissances suffisantes pour l’utilisation des outils de bureautique, et des explications complémentaires sont relativement faciles à acquérir sur Internet.
Cependant, lorsque le projet est plus ambitieux ou plus complexe, il peut être nécessaire d’utiliser des outils plus spécialisés, par exemple au niveau de la gestion d’une base de données, ou des outils statistiques ou de restitution de résultats.
Dans ce cas, il sera presque obligatoire de disposer d’un appui technique pour ces outils, leur connaissance détaillée n’étant que du niveau d’un professionnel. Ce niveau d’appui peut devenir problématique dans la durée, problème examiné ci-dessous.
En effet, nos projets se caractérisent par leur durée, et leur nécessaire flexibilité. Un projet s’étend facilement sur une année (scolaire), et souvent deux ou trois. Cela résulte de la charge de travail, souvent importante lors des phases de codage/saisie et vérification, mais aussi des retours en arrière, à la suite de découvertes, d’axes de recherche complémentaires ou d’erreurs, qui entrainent une reprise partielle de travaux déjà effectués.
Il faut donc s’assurer de disposer du temps nécessaire au projet (les thèses d’état ont un délai limité), mais aussi de disposer d’aides et d’appui nécessaires sur la durée.
Ce dernier point rejoint également une autre préoccupation parfois rencontrée : la maitrise des outils. Certains historiens, en général étudiants, ont des réticences à utiliser des outils « sophistiqués » (voir ci-dessous), car ces outils nécessitent l’assistance de spécialistes (en général informaticiens ou statisticiens).
Cela vient souvent de la peur de ne pas maitriser totalement, de bout en bout, les travaux de leur thèse, et aussi, accessoirement, de ne pas disposer de cet appui sur la durée.
Les outils
Il n’est pas prévu ici de réaliser un panorama complet des outils disponibles pour les travaux de recherche en Histoire, mais de décrire les outils simples ou du moins à la portée des chercheurs.
Petite restriction : je prends en compte ici uniquement l’utilisation de PC, ou micro-ordinateurs, ou ordinateur personnel. En effet, je ne vois pas comment réaliser des travaux de saisie sur un tableur sur votre téléphone, même sur une tablette, sans parler du développement d’une Base de Données.
Une première discussion, très technique et vite évacuée, concerne le système d’exploitation, c’est-à-dire la base, le « fond », du fonctionnement de votre ordinateur. Pour la plupart d’entre vous, ce sera Windows, de Microsoft (75%), ou alors MacOs d’Apple (15%). Je ne prends pas en compte les systèmes plus exotiques tels que Linux, et considérant la restriction ci-dessus, je ne mentionnerai pas non plus Android ou iOS d’Apple.
Outils bureautiques
Ensemble des techniques et des outils tendant à automatiser les activités de bureau (Wikipédia).
Pour les amateurs comme nous, cela comprend un traitement de texte, un tableur, un logiciel de présentation, c’est ce que nous utilisons tous les jours, à la maison ou au bureau. Peuvent s’ajouter des logiciels plus spécialisés, comme la PAO (Publication Assistée par Ordinateur), des gestionnaires de base de données ou des clients de messagerie.
Ces outils permettent de réaliser la grande majorité des tâches de l’historien, telles que décrites précédemment. Ils se présentent en général sous forme de « suite », la plus connue et la plus utilisée étant Microsoft Office (les chiffres de diffusion ne sont pas connus).
La suite Microsoft a deux défauts, elle est payante, ce qui peut être rédhibitoire pour des étudiants désargentés, et elle est le monopole (logiciel propriétaire) d’un des géants capitalistiques de l’informatique (voir la discussion « maitrise » ci-dessous).
Une autre solution est l’utilisation de logiciels dits « logiciels libres »,
Wiki : Un logiciel libre est un logiciel dont l’utilisation, l’étude, la modification et la duplication par autrui en vue de sa diffusion sont permises, techniquement et juridiquement [1]
Pour les suites bureautiques, le plus répandu est LibreOffice, dérivé du célèbre OpenOffice, suite recommandée dans les administrations françaises.
Techniquement, les différences entre MS Office et LibreOffice ne sont pas très grandes pour un usage courant. Des différences significatives apparaissent dans des niveaux d’utilisation supérieurs, par exemple entre Microsoft Access et LibreOffice Base.
La force de Microsoft est que sa suite est utilisée dans pratiquement toutes les entreprises, et que rentré le soir à la maison on n’a pas envie de se mettre à apprendre une ergonomie bien différente.
Second niveau d’outils
Il faut bien être conscient que les outils bureautiques seront suffisants dans la majorité de nos projets, et qu’il ne sera pas utile de faire appel à des applications sophistiquées.
Si nécessaire, il existe beaucoup d’outils qui peuvent être employés pour des cas plus étendus ou plus complexes, ou techniquement singuliers (nota : sauf exception, les logiciels cités ci-dessous sont dits « libres », donc gratuits).
En ce qui concerne les bases de données, MS Access est une solution utile et assez facile à mettre en œuvre, mais est payante, intégrée à MS Office. Dans la suite LibreOffice existe également un gestionnaire de Base de Données, LibreOffice Base.
Pour une base étendue ou partageable (plusieurs utilisateurs en réseau), des solutions plus complexes peuvent être utilisées, comme MySQL ou SQLite, qui de plus existent en logiciel libre.
Du côté des outils statistiques, le plus répandu est R (la lettre R), qui est un langage de programmation de travaux statistiques, et également outil, environnement de travail de ce langage. A peu près tout ce que vous souhaitez faire en statistique est possible avec R.
Ce langage attaque toutes les bases de données ou tableurs pour extraire les données, et dispose également d’une très grande gamme de présentation de résultats.
Enfin, les recherches historiques ont souvent besoin d’une représentation géographique des résultats. Un des outils les plus utilisé (en français) est Philcarto, logiciel de cartographie, qui propose par exemple tous les fonds de carte imaginables sur la France.
Création d’applications
Nous avons vu que les outils simples peuvent être très utiles dans nos recherches. Pour les cas particuliers ou complexes, des outils plus sophistiqués peuvent être nécessaires. Il y a cependant des cas ou la création d’applications informatiques (programmes) s’avèrent nécessaire.
Dans les exemples des chapitres précédents, plusieurs travaux ont été réalisés à l’aide d’outils créés spécifiquement. Deux catégories ont été présentées, le traitement de données textuelles, et les bases de données volumineuses et complexes.
Données textuelles
Les outils standards ne sont souvent pas vraiment adaptés aux traitements des mots des textes. Chaque cas est particulier, pas de point de convergence entre les inventaires des archives DD et l’analyse des titres de la photothèque, à part qu’il s’agit de mots.
Il est donc en général nécessaire de créer de petits programmes, souvent très simples, qui permettent d’analyser ces textes. Chaque cas est spécifique, et souvent plusieurs petites étapes sont nécessaires. La simplicité de ces traitements permet en général une maitrise par l’historien.
Base de données complexe
La deuxième catégorie, celle des cas complexes, nécessite des applications informatiques, afin de traiter des données qui sont au-delà des possibilités d’un tableur. Malheureusement, cette complexité entraine la perte de la maitrise par l’historien, car elle implique, en général, l’assistance d’un spécialiste. C’est le cas de l’application présentée en chapitre 3.
Les outils (langages)
Un premier groupe de langages comprend les compléments des suites bureautiques, utilisés principalement pour leur capacité d’intégration des autres outils de la suite comme le tableur ou la base de données. On retrouve ici la dichotomie propriétaire VS libre, Visual Basic pour Microsoft, Basic pou LibreOffice.
Il y a ensuite les langages de programmation proprement dits. Depuis les débuts de l’informatique dans les années 60 sont apparus ces langages qui permettaient un développement facilité d’applications informatiques.
Les premiers furent le Cobol et le Fortran, le Pascal fut beaucoup utilisé en France. Ces précurseurs était construit pour des traitements « séquentiels », c’est-à-dire une collection d’enregistrements (fichier ou cartes perforées) était lue et traitée en séquence.
Ensuite sont apparus les langages plus adaptés au « temp réel » (dit aussi client-serveur), c’est-à-dire le traitement individuel sur des écrans connectés. On trouve au début le C, puis le C++, Lisp ou Prolog, ainsi que Java. Beaucoup de langages sont spécialisés dans des domaines particuliers et limités, par exemple R cité plus haut est aussi un langage et un environnement spécialisé dans les statistiques.
Aujourd’hui, le plus utilisé semble être Java, sous différentes formes (classique, application Web, ou sous Android). Par exemple, sauf pour l’application du chapitre 3, les autres exemples cités dans les chapitres précédents sont réalisés en Java. Vous aussi vous utilisez des programmes en Java, notamment les applications sur votre téléphone ou l’informatique embraquée de votre voiture.
Ces langages sont accompagnés de plusieurs environnements de développement qui facilitent énormément le travail, par exemple Eclipse et NetBeans.
Sauf exception, tous ces langages, ainsi que les environnements de développement, sont libres de droit. Ils sont en général propriétés de grands groupes comme Oracle, mais après trente ans de controverse juridique, on peut assez librement les utiliser.
Et l’IA ?
Mes expériences avec l’IA sont très partielles et non conclusives pour l’instant.
Il y a cependant une tâche qui pourra certainement bénéficier de ce mécanisme, c’est le traitement des textes (des mots), comme défini ci-dessus. Il est en effet possible de remplacer les petits programmes par des interrogations de l’IA, et donc de s’éviter la tâche de programmation.
Mais dans ce cas, l’intelligence est dans l’art de poser la question, la machine ne faisant qu’exécuter mécaniquement le processus.
Enfin, dernier développement de l’IA, non pas exécuter des tâches, mais générer le programme informatique réalisant une tâche. Au-delà de mes connaissances, mais à creuser !
[1] Une discussion existe sur différentes catégories : freeware, open source ou logiciel libre. Nous ne présenterons pas ces nuances, pour nos besoins ici ce sont surtout des logiciels « gratuits », par opposition aux logiciels propriétaires, payants.